
Stop Internal AI Risk at the Source
Meshulash gives enterprises real control over prompt injection, jailbreaks, AI identity/IAM gaps, and brand-damaging leaks—across browsers, IDEs, internal apps, and agent workflows.

Why Internal AI Risk Is Different
Most breaches start inside the perimeter. When AI can act on data and tools, small mistakes become public incidents.
Prompt Injection & Jailbreaks
Hidden or crafted instructions make models ignore rules, escalate privileges, or exfiltrate data.
No IAM for AI Identity
Agents and connectors run under shared tokens or broad service accounts; actions aren't scoped to a user or role.
Leakage & Brand Harm
Sensitive content and unsafe outputs (PII, IP, client data) can surface in prompts, uploads, or generated responses, damaging trust and reputation.
Opaque Activity
Without unified logs, security can't prove who did what, with which model, tool, or dataset.
Injection & Jailbreak Defense—Before Damage Happens
Meshulash evaluates context and intent at the point of use. The endpoint layer redacts and validates prompts and files before they reach the model; responses are checked on the way back. Policies can block, redact, warn, or log when we detect jailbreaks, indirect prompt injection, or privilege-escalation attempts so risky actions never execute.

AI Identity & Access
With the MCP Gateway, admins decide which MCP servers are allowed, which tools can be used, and which resources each tool can reach, per team and role. Least-privilege is enforced by policy, and every tool invocation is tied to identity for audit and investigations.

Secure-by-Design Apps & Agents (API/SDK + Security Server)
Build internal and external AI apps that are secure from day one. Route requests through the Meshulash security server (self-hosted or managed): it identifies context, intent, IP, and PII, then blocks, redacts, or allows based on policy—so apps and automations (e.g., n8n, OpenAI agent workflows) can't process sensitive data or run unsafe actions.

Prevent Leaks. Protect Reputation.
Meshulash screens documents before upload, redacts sensitive fragments before they are sent to the model, and constrains access to approved models and endpoints. Unsafe or off-brand outputs can be caught by policy before they reach users, reducing legal exposure and brand risk while allowing external AI tools to continue working.

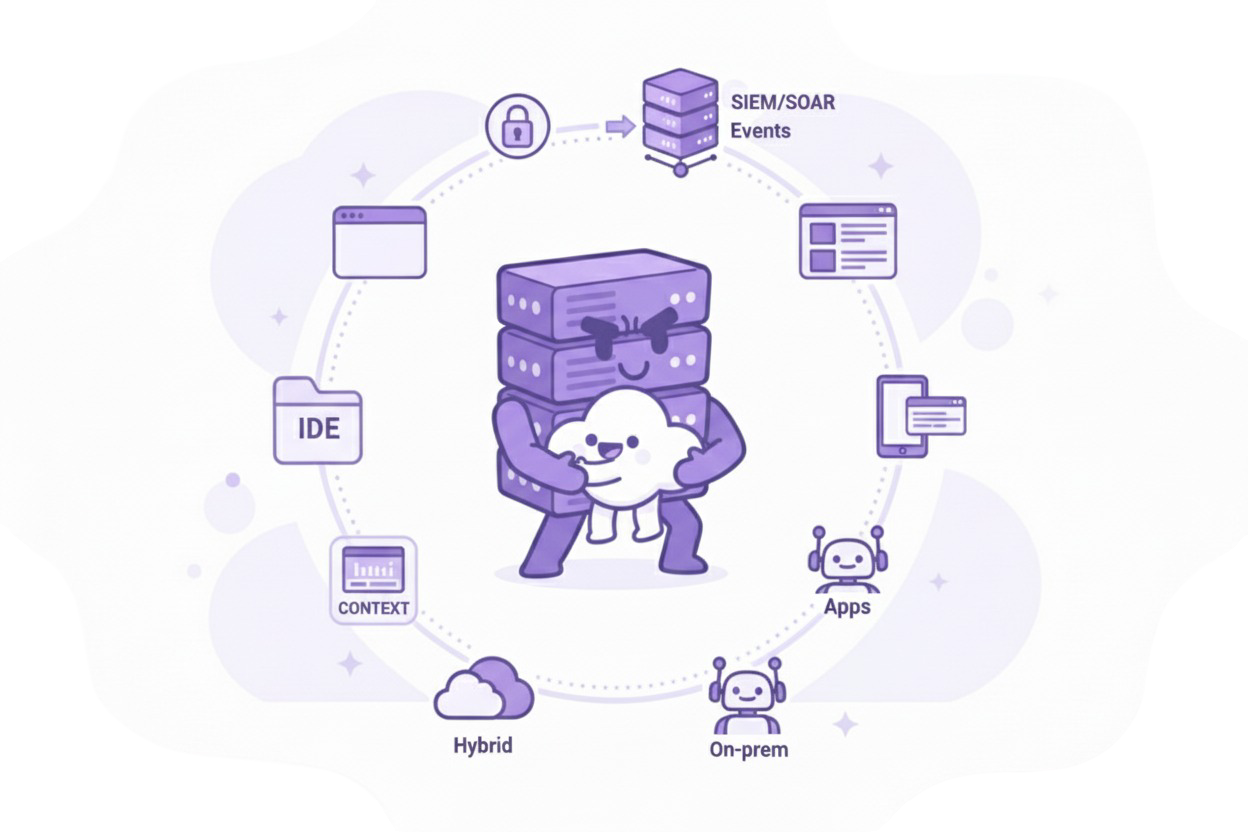
One Control Plane. Your Deployment Model.
Enforce the same policies across browsers, IDEs, apps, and agents—cloud, hybrid, or on-prem. Use SSO for identity, stream events to SIEM/SOAR for correlation and response, and manage exceptions without blanket bans or manual firefighting.
Frequently Asked Questions
Quick answers to common questions
We evaluate intent and context pre-execution at the security layer. Policies decide to block, redact, warn, or log so malicious instructions never reach tools or data.
Many AI agents and connectors run with shared or over-broad credentials. MCP IAM (via the MCP Gateway) scopes each tool to specific resources and environments, tied to user/role—so actions are attributable and least-privilege.
On-network redaction for prompts and files, document screening before upload, and model/endpoint allowlists. The security server applies policy decisions (block/redact/allow) based on detected PII/IP/context/intent.
Yes. Use the API/SDK + security server to enforce the same policies across internal apps and public-facing experiences, plus n8n and OpenAI agent workflows.
No. Guardrails run quietly at the endpoint and gateway; exceptions are managed through policy, making productivity and safety move together.